Continuous integration is rightly a hot topic in today’s world where the time desired to bring products to market is ever shrinking. Database lifecycle management is a key part of this, and generally database professionals have been slow to adopt continuous integration methodologies, often hiding being frameworks such as ITIL to point to issues of safety and caution.
It’s undeniable that a database release is a much more complicated beast than an application release, due to one really key part of a database: data. Unlike an application, you can’t just destroy your database and start over with a clean slate at every release; if you did, your data, and likely your business, will be gone. Whoops. This is where I start getting a little nervous with some of the options available in SSDT deployments, such as this one:-
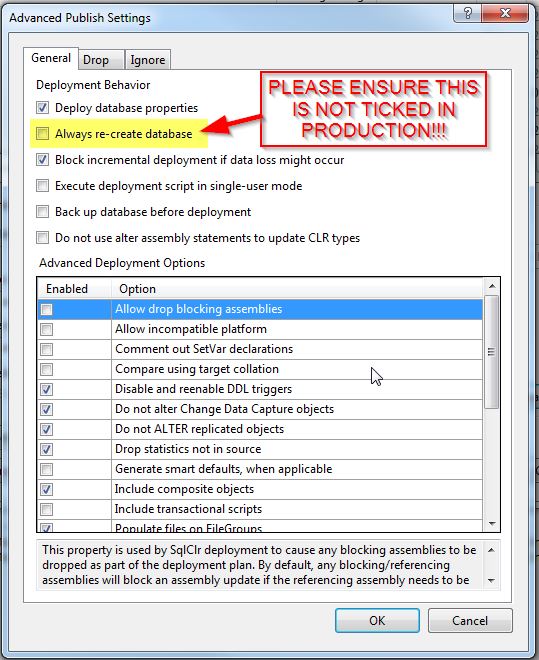
I’ve recently been working alongside some of our .NET architecture teams to try and automate our SQL Server database deployments. I’m absolutely, 100%, all for this, as database deployment really does need to be brought kicking and screaming into the 21st century, and DBAs really do need to start chilling out a little bit and losing some of that control freakishness and desire to say “NO” all the time.
However, during this work, there are several use cases that have cropped up that have definitely given me pause for thought (the Always re-create database not withstanding), and, left unchecked, would result in potentially disastrous effects on a live database. They’re also stuff that you need a bit of database knowledge for, and are very dependent on data, in particular volume. Each one of these issues worked without problem on the development systems our devs were using, with tiny datasets; but in the real world, with GBs of data, these would make releases an utter nightmare. I’ll spread these over a few blogs; here’s the first:
-
Ignore partitions schemes (unticked by default).
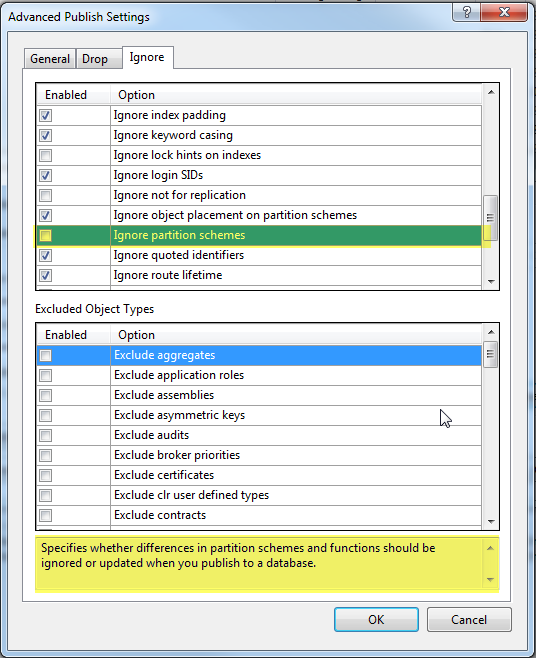
Not everyone uses partitioned tables. But, if you are, chances are, they’re big. Because that’s why we partition tables, to make maintenance, archiving and so on, a lot easier as the table is broken up into chunks. In addition to this, generally speaking, partition functions tend to be based on something like a date, e.g. monthly, quarterly and so on. It’s not then uncommon to see a stored procedure that manages archiving off a partition from, say, 12 months ago, and changing the partition function to add in the new month. This is all good, and typically how I’d want partitioning to work.
So, when I created a test deployment for a database with a partitioned table, where I was expecting a single other change (I’d added a new stored procedure), I was utterly horrified to see the results of the script:-
- Drop any constraints on the table. (I’m wondering now, I didn’t change any constraints?!?)
- Create a new table (Uh oh, this is starting to look really bad) with the same schema as the partitioned table, on the default filegroup. (More on the default filegroup later).
- Opens a transaction.
- Sets the isolation level to be serializable.
- Copy the data from the original table, into the new table. (Remember, this is a BIG partitioned table). In a single statement. (Watches transaction log get really big).
- Drops the original table.
- Renames the new table to the original table name. (So we now have an UNPARTITIONED behemoth of a table….)
- Commits the transaction. (Assuming the big insert didn’t fill my log, that is).
- Returns the isolation level to read committed.
- Drops the partition scheme and the partition function. (Curious…)
- Creates a new partition scheme and partitioned function, with the boundaries set 2 years in the past. (Oh dear, I see what’s happening…..)
- Opens a new transaction and sets isolation level to serializable.
- Creates a new table (Again?!?! WTF?!?!) with the same schema as the partitioned table but this time on the newly created partition scheme.
- Copies the data from the unpartition table, into the newly, incorrectly partitioned, table (Repeat all the comments above about transactions and the transaction log).
- Commits, and returns to read committed.
- Recreates all the non clustered indexes on the table.
- Then it created the new stored procedure, the bit I actually wanted to happen.
The issue was that the partition scheme checked in to TFS was as the state of the table when it was created:- four quarters starting from the 1st Jan 2014. Over time, the stored procedure that manages the partition had switched some of these off and rolled forwards. However, as this is a result of a procedure and not a manual change, the script in TFS was not updated. The results of this would be pretty horrendous in a live situation, as we’d end up with 80GB of data being rewritten out, twice, and also all the data ending up being in a single, huge partition (quarter four of 2014 onwards). When the procedure next kicked in, it would end up splitting a full partition several times in order to move it all back to where it needed to be, before the next release undid everything again. There are further potential issues with swapping a table about: imagine if there were other tables with foreign keys to this one!
One solution would be to keep the script in TFS up to date with the partition scheme as it is in live, but this sort of negates the process of using a procedure to maintain this for us. If we’re doing this, we might as well make the switch out a manual task; and I hate manual tasks.
Happily, ticking the box to ignore this means that the partition scheme is ignored and all this madness doesn’t happen. If I actually wanted to do the partition scheme change, I could either turn it back off, or manually deal with it. The important thing for me, is that this is a part of SQL Server that doesn’t have as widespread knowledge as some, and that in Dev, with a small dataset, the above process isn’t really a problem. It’s only a gotcha when you move to live, which might be too late if the issue wasn’t caught as a potentially huge problem.
Next up, in the next blog, will be more about how the default filegroup works with an SSDT project and deployment!

[…] my previous post, I alluded to some of the issues I’ve found using SSDT based deployments into a live […]
LikeLike
[…] on from this, and already seen in Part 1 where I lambasted the awful way that partition scheme changes happen, is that almost anything that […]
LikeLike